
 0 saved
0 saved
 31.3K views
31.3K views




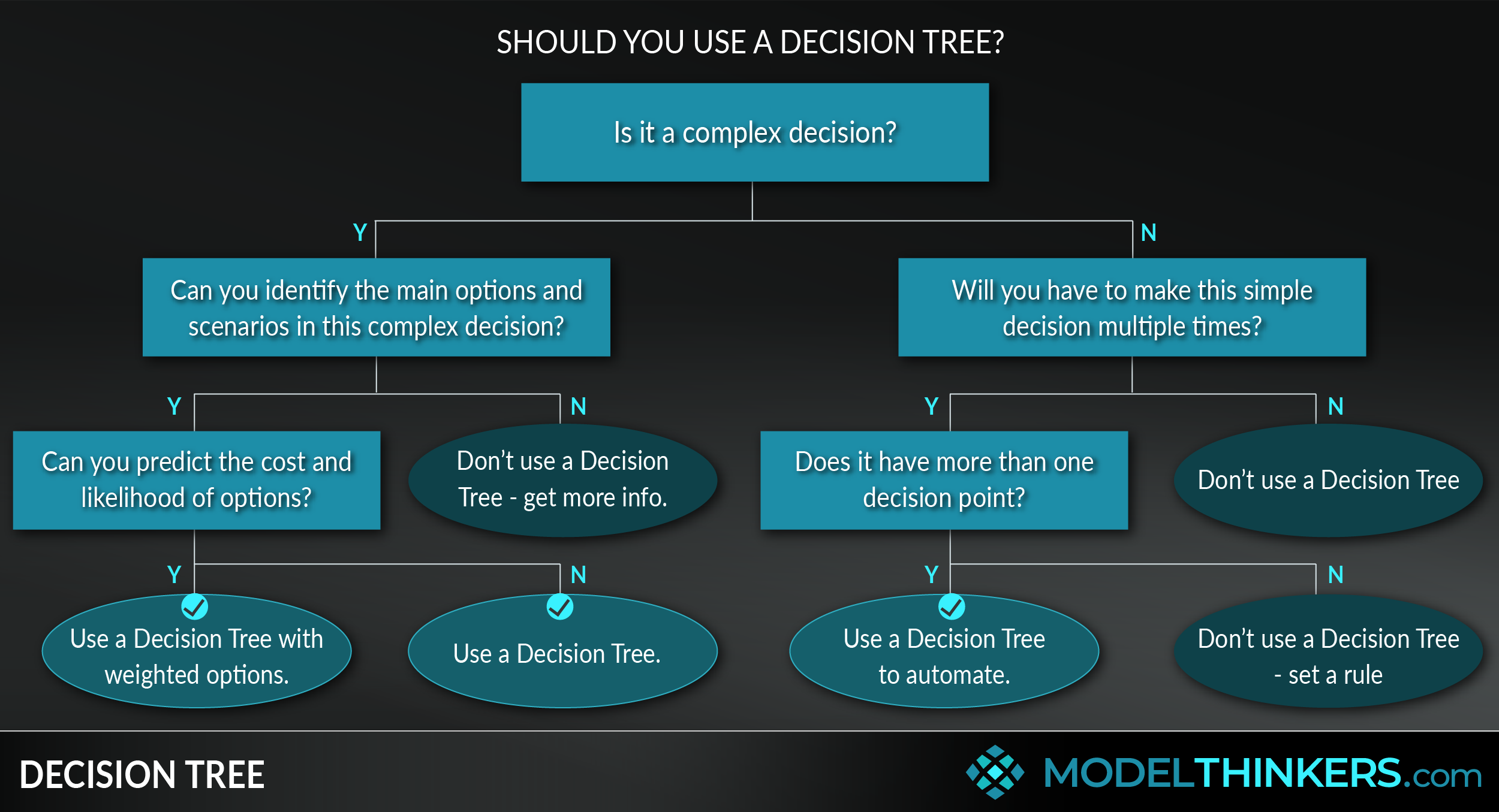
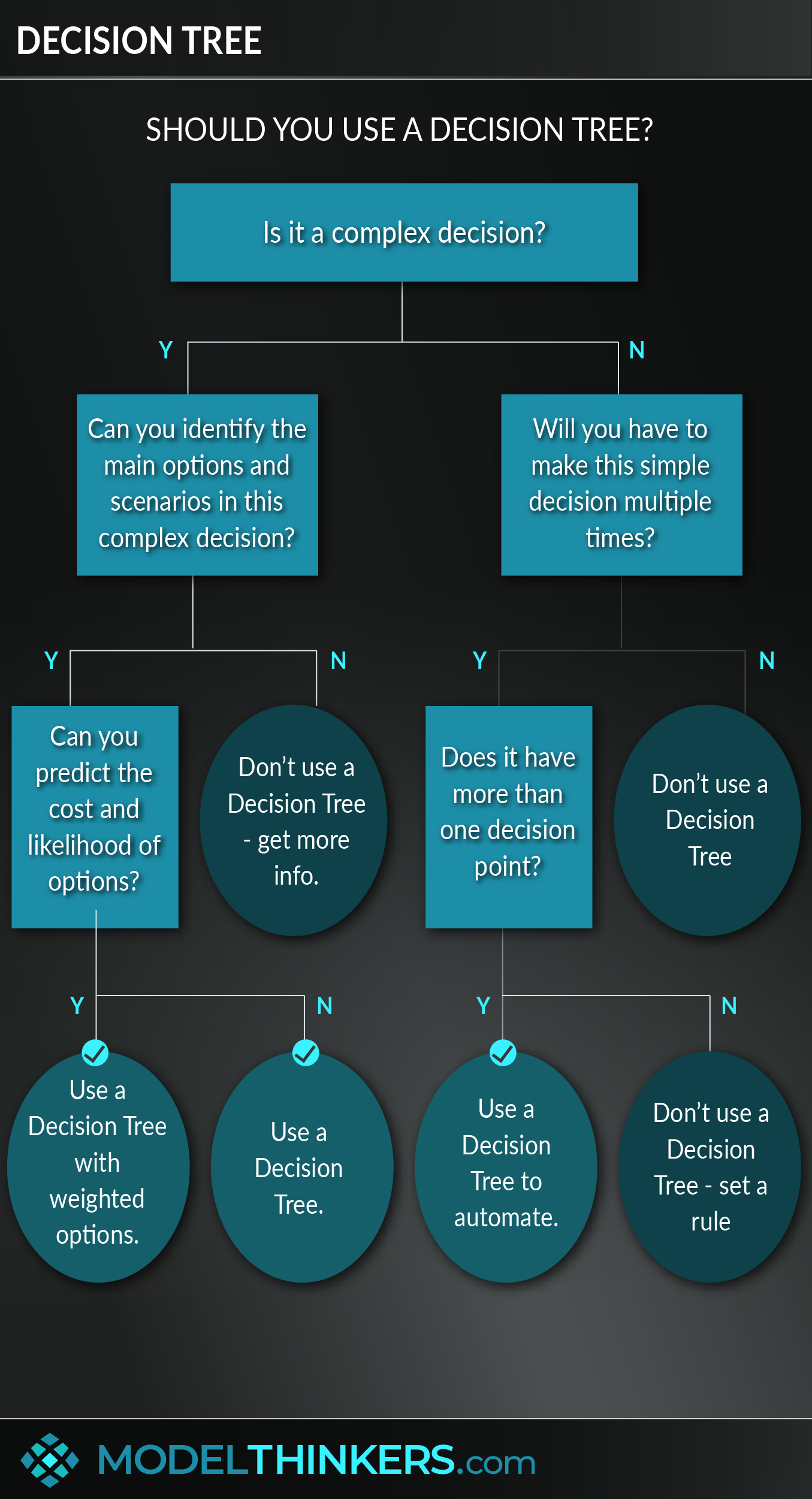
Decision Trees are used in domains as diverse as manufacturing, investment, management, and machine learning, and they're a tool that you can use to break down complex decisions or automate simple ones.
A Decision Tree is a visual flowchart that allows you to consider multiple scenarios, weigh probabilities, and work through defined criteria to take action.
THE ANATOMY OF A TREE.
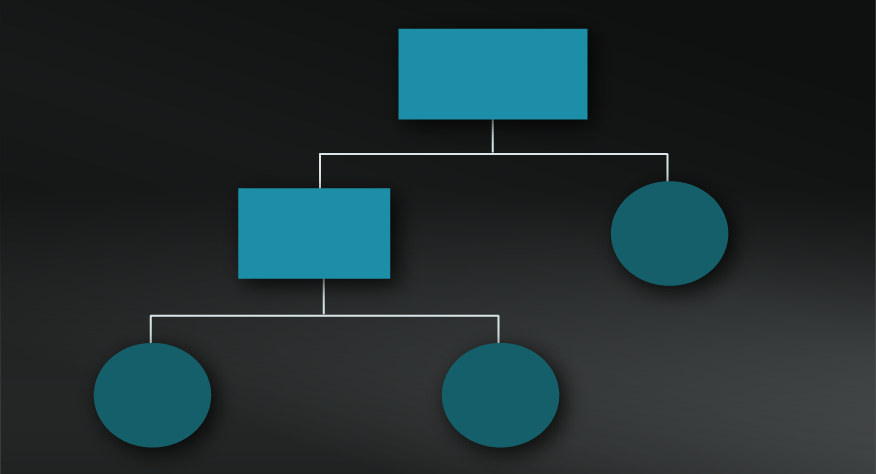
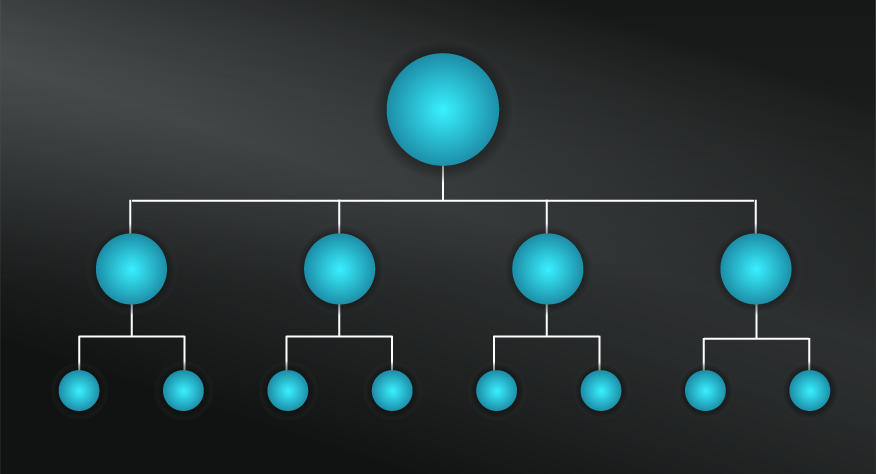
Decision Trees start with a single node that branches into multiple possible outcomes based on a test or decision. Each branch has additional nodes that can continue to branch into additional possibilities. It’s what you’re likely doing unconsciously, whenever you break down an issue using clarifying questions or criteria.
CATEGORISE OR PREDICT.
We find it most useful to consider Decision Trees in the context of one of two use cases.
-
Categorise options to decide: methodically break down a large, complex problem with stepped criteria until you reach a clear action point.
-
Predict possibilities: assign probabilities and costs to potential outcomes to assess choices based on the ‘expected value’ of those options. This can be applied to potential income from various investment opportunities, right through to risk assessment analysis. See the In Practice section for an example.
It’s worth noting that Machine Learning categorises Decision Trees differently, as Categorical Variables, which are binary Y/N tests; and Continuous Variables, which are ranges such as time or distance. However, such classifications are less useful for broader applications of this model. Again, view the In Practice section below to view different types of Decision Trees.
FOR CLARITY IN COMPLEXITY AND SIMPLE AUTOMATION.
This model can help you with both simple and complex decision-making challenges.
-
For complex decisions, Decision Trees will help you systematically break down a problem into its component decision points. Their visual nature supports collaboration and discussion. Further, assigning probability and costs to alternative scenarios will help identify the expected value behind a decision and assist in interrupting unconscious bias.
-
For relatively simple decisions that have more than one decision point, Decision Trees can help you to reduce cognitive load by working through a consistent, informed automatic pilot. See the ‘Should I keep this’ example in the In Practice section below.
GROWING THE TREE.
The starting point for a Decision Tree is defining the problem you are solving for and identifying the first, most clarifying criteria or test to assign as your first node.
After that, it’s a case of choosing the most useful categories that help further break down possible options and the problem into clear components. If you are using probability and cost impact as an additional method to assess options, simply multiply the probability and amount of money for each option to determine an average comparison. See the In Practice section for a worked example of this.
IN YOUR LATTICEWORK.
Decision Trees play well with a range of other models. Use Framestorming and/or the 5 Whys to ensure that you’re answering the most powerful question before you start. Assigning expected values for each scenario is essentially the application of both Probabilistic Thinking and a Cost-Benefit Analysis.
You can go deeper into your decision analysis with Second-Order Thinking, and we recommended using Decision Trees with your Cynefin Practice — particularly in the Complicated and Clear domains.
-
Define the problem.
Establish the overarching issue or problem that you are wanting to solve or clarify. E.g. ‘Should I use a Decision Tree?’
-
Brainstorm criteria or questions to clarify the problem.
Make a list of criteria that will help break down the problem. Continuing the example, this might include ‘is it complex or simple?’; ‘does it have more than one decision point?’; and 'can I determine probability and costs of the options?’ ‘
-
Identify the most clarifying question as your starting node.
One of the questions you’ve brainstormed will make the clearest, fastest cut through to reach an answer for your problem — that should become your starting node. In our continuing worked example, this would likely be the ‘simple or complex’ question given that is the most high-level clarifying criteria of the ones brainstormed.
-
Establish further branches as required.
For each possible option, consider whether it comes to an end result or requires another test/ question to consider further options. In our worked example, this involves creating a hierarchy of the existing criteria or questions and considering appropriate actions for each choice. See the diagram at the top of this model for how this plays out.
-
Consider probabilities and impacts for each option.
Depending on the nature of the decision, it might be appropriate to calculate ‘expected value’ of each option. This can be achieved by assigning probabilities and impacts (e.g. costs or income) for each option. The probability multiplied by the impact number will return an average ‘expected value’ for each alternative, which can inform your decision. This is not appropriate for our worked example, but view the In Practice section for an example.



Decision Trees are only as useful as the categories and criteria you have established upfront. That process of setting criteria can miss important factors or even be organised in a counter-intuitive order, making the application of a Decision Tree more of a hindrance than a help.
For probabilistic-based Decision Trees, a slight change in probabilities or data can be amplified through the tree, leading to very different results. Even if the probabilities and costs are known, the expected value for each option that is calculated is not representative of real outcomes — they simply average out the extremes.
Continuing on that theme, sometimes Decision Trees can lose the ‘big picture’ by focusing on the immediate stepped process. It might lead to bigger, less predictable opportunities or issues being accounted for because they don’t fit into the normal presets of a Decision Tree.
Which to invest in?

From Advanced Management Science.
Based on the above, the expected value of each node can be calculated as follows:
-
Expected value of node 2: 0.60($50,000) + 0.40($30,000) = $42,000
-
Expected value of node 3: 0.60($100,000) + 0.40(-$40,000) = $44,000
-
Expected value of node 4: 0.60($30,000) + 0.40($10,000) = $22,000
Again, this does not guarantee an outcome for each option, it merely represents a predicted average for each scenario. Based on these figures, node 3 would be the preferable option.
Should you get rid of this?

From Smart About Money. This is an example of a rule-based decision process that can reduce cognitive load and help you act quickly. Rather than drawing on your mental effort for each piece of clothing or junk in your house, you can simply work through this decision tree to achieve consistent, predictable results.
Do you say ‘Hi’?

From Knockknockstuff. This is just too funny so we had to include it.
f
Decision Trees are something that we have used unconsciously since the rise of critical thought, however, it’s unclear who first named or captured the approach as a concept.
In this very comprehensive exploration of Decision Tree history by Mike Hunter on StackExchange, he identified the first reference of Decision Trees to William Belson in a 1959 paper entitled ‘Matching and Prediction on the Principle of Biological Classification.’ However, Hunter goes onto point out that it could be argued that the Babylonian's use of quadratic equations and nonlinear variables or Aristotle’s book on Categories both employed hierarchies that were similar in concept to Decision Trees.
Computer science researcher Ross Quinlan is considered to be one of the first people to apply Decision Trees to Machine Learning in 1975.
 My Notes
My Notes
Oops, That’s Members’ Only!
Fortunately, it only costs US$5/month to Join ModelThinkers and access everything so that you can rapidly discover, learn, and apply the world’s most powerful ideas.
ModelThinkers membership at a glance:

“Yeah, we hate pop ups too. But we wanted to let you know that, with ModelThinkers, we’re making it easier for you to adapt, innovate and create value. We hope you’ll join us and the growing community of ModelThinkers today.”
You Might Also Like:
- Actionable summaries of the world's most powerful ideas.























































Subscribe now and download this practical guide to transform your thinking, plus recieve one short, powerful and actionable idea in your inbox each month.